CS224n Lecture 2 Word2Vec
Word2Vec
本次课程介绍了Word Embedding的常用方法——Word2Vec的基本原理,与简单的函数推导、训练过程。
#####传统的词义表示
传统方法如Wordnet,提供了英语词汇的分类信息
存在大量的同义词资源,但是很难利用;缺失新词汇;主观;很难计算词的相似度
早期NLP工作将单词视为原子符号,即one-hot表示(一个为1,其余为0),维数爆炸,而one-hot向量没有天然相似性
分布相似性
分布相似性(Distributional similarity)即通过词语的上下文,能够得到大量表示其含义的词,是线代统计自然语言处理最成功的思想之一
分布式表示(Distributional representation)即用密集向量表示词汇的含义
Word2Vec
basic idea:定义一个模型,通过中心词预测上下文词汇,预测的概率为: $$ p(context\mid wt) = \dots $$ 损失函数即为: $$ J = 1 - p(w{-t}\mid wt) $$ $w{-t}$表示除$w_{t}$之外的其他上下文词汇
这种思想并不是什么新想法(Rumelhart et al., 1986),Bengio et al. (2003)将其用作词汇表示,当时没什么人关注,因为DL还不流行。Collobert & Weston(2013)认为可以只需要得到词的表示,而不需要language model。这就是word2vec(Mikolov et al. 2013)模型,简单、可扩展。
word2vec是一个软件,包括很多东西:两个生成词向量的方法(Skip-grams & Continuous Bag of Words)和两个有效的训练方法(Hierarchical softmax & Negative sampling),但是本节课只介绍skip-gram和一种低效率的训练方法(最最基本的Naïve softmax)
Skip-gram
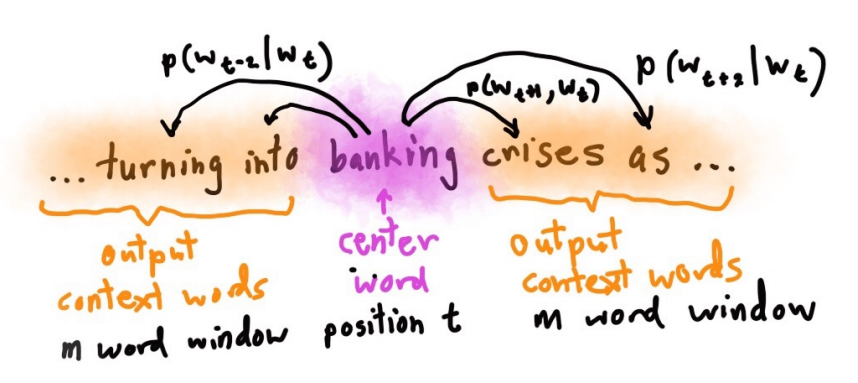
在每一步选取一个单词,尝试预测一定范围内的上下文单词。模型定义了一个概率分布,即给定一个中心词汇,某个单词在它上下文中出现的概率。选取词汇的向量表示,尝试让概率分布最大化。
需要注意,模型中对一个单词只有一个概率分布。
定义一个半径m,从中心词汇开始,预测m距离之内的单词,目标函数为: $$ J’(\theta)=\prod{t=1}^T \prod{-m\le j\le m,j\ne0}p(w_{t+j}\mid w_t;\theta) $$ 对文本中的每个单词,定义一个围绕中心单词的2m的窗口,得到一个概率分布,设置模型的参数目的是使概率尽可能的高,$\theta$为即模型的参数,即词汇的向量表示。
取对数可以把积转化为和,在数学上更简单。得到负的对数似然,也就是要最小化的目标函数: $$ J(\theta)=-\frac{1}{T} \sum{t=1}^T \sum{-m\le j\le m,j\ne0}\log p(w_{t+j}\mid w_t) $$ 负的对数似然意味着使用交叉熵损失函数(后面会讲)。
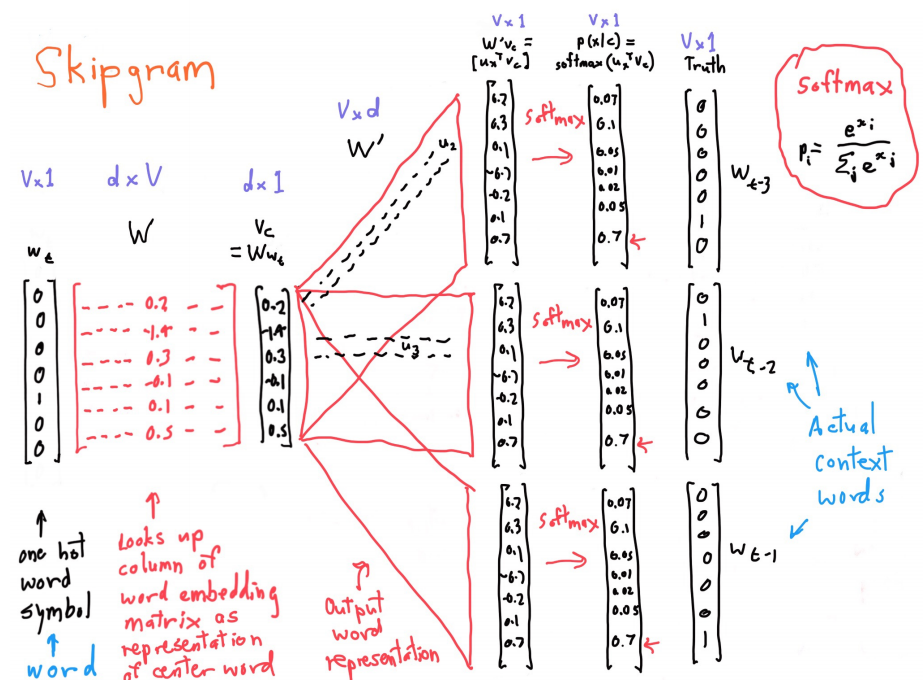
概率分布的形式: $$ p(o\mid c)=\frac{\exp(u_o^Tvc)}{\sum{w=1}^V \exp(u_w^T v_c)} $$ o和c代表输出单词和中心单词的索引
点积的结果为一个数值,这里使用了softmax函数,将数值转化为概率。
需要注意的是,每个单词有u和v两个向量,两个向量相互独立,使得优化时不会互相耦合。
Sentence Embedding
介绍论文《A Simple but Tough-to-beat Baseline for Sentence Embeddings》, Princeton University, ICLR 2017。这一部分由Danqi Chen讲授。
Sentence Embedding可以用来计算句子的相似度、句子分析(如情感分类任务)等。
得到Sentence Embedding的方法有:
- 词袋 Bag-of-words(BoW)
最简单的方法,词向量取平均
v(“natural language processing”) = 1⁄3 (v(“natural”) + v(“language”) + v(“processing”))
Recurrent neural networks
Recursive neural networks
Convolutional neural networks
这篇论文介绍了一种简单的无监督学习方法:
第一步是计算向量表示的平均值,每个单词有权重值

权重表示为$\frac{a}{a+p(w)}$ ,其中$a$为常数,$p(w)$为单词$w$出现的频率
第二步减去在第一主成分上的投影(PCA)

基本思路是:给定上下文中,一个词的出现概率由上下文和作为平滑项的词频决定(这儿没太听懂)
Word2Vec 训练
$$ p(o\mid c)=\frac{\exp(u_o^Tvc)}{\sum{w=1}^V \exp(u_w^T v_c)} $$
要调整参数,也就是向量,使得负的对数似然项最小化。
求导数: $$ \frac{\partial}{\partial v_c}\log\frac{\exp(u_o^Tvc)}{\sum{w=1}^V \exp(u_w^T v_c)} $$
$$ \frac{\partial}{\partial v_c}[\log \exp(u_o^Tvc)-\log{\sum{w=1}^V \exp(u_w^T v_c)}] $$
对前一部分$\frac{\partial}{\partial v_c} \log \exp(u_o^Tv_c)$ ,变成 $\frac{\partial}{\partial v_c} (u_o^Tv_c) \rightarrow u_o$
对后一部分$\frac{\partial}{\partial vc}\log{\sum{w=1}^V \exp(u_w^T v_c)}$ ,使用链式法则
$$
\begin{align}
&\frac{\partial}{\partial vc}\log{\sum{w=1}^V \exp(u_w^T vc)}
&= \frac{1}{\sum{w=1}^V \exp(u_w^Tv_c)}\cdot\frac{\partial}{\partial vc}\sum{x=1}^V \exp(u_x^T vc)
&= \frac{1}{\sum{w=1}^V \exp(u_w^Tvc)}\cdot \sum{x=1}^V \frac{\partial}{\partial v_c} \exp(u_x^T vc)
&= \frac{1}{\sum{w=1}^V \exp(u_w^Tvc)}\cdot \sum{x=1}^V \exp(u_x^T v_c)\cdot \frac{\partial}{\partial v_c}(u_x^Tvc)
&= \frac{1}{\sum{w=1}^V \exp(u_w^Tvc)}\cdot \sum{x=1}^V \exp(u_x^T v_c)\cdot ux
&= \sum{x=1}^V \frac{ \exp(u_x^T vc)}{\sum{w=1}^V \exp(u_w^Tv_c)}\cdot ux
&= \sum{x=1}^Vp(x\mid c)\cdot u_x
\end{align}
$$
得
$$
\frac{\partial}{\partial v_c}\log\frac{\exp(u_o^Tvc)}{\sum{w=1}^V \exp(u_w^T v_c)} = uo - \sum{x=1}^Vp(x\mid c)\cdot u_x
$$
梯度下降
前面是一些梯度下降的基本知识,不再赘述。
使用随机梯度下降(SGD),即选取文本中的一个位置,对所有的参数求解梯度,然后前进一小步。这种估计很粗糙,但是实际证明很有效。