CS224n Lecture 6 依存语法分析
依存语法分析
语言结构的描述
语言结构的第一种描述,是短语结构将词组织起来。
短语结构如:
the cat
a dog

the large cat in a crate可以被分解成几个短语
可以用上下文无关文法(CFG)描述
关于语言结构的另一种描述就是今天要介绍的依存句法结构,通过找到句子中的每一个词依赖的部分来描述句子结构。
依存句法
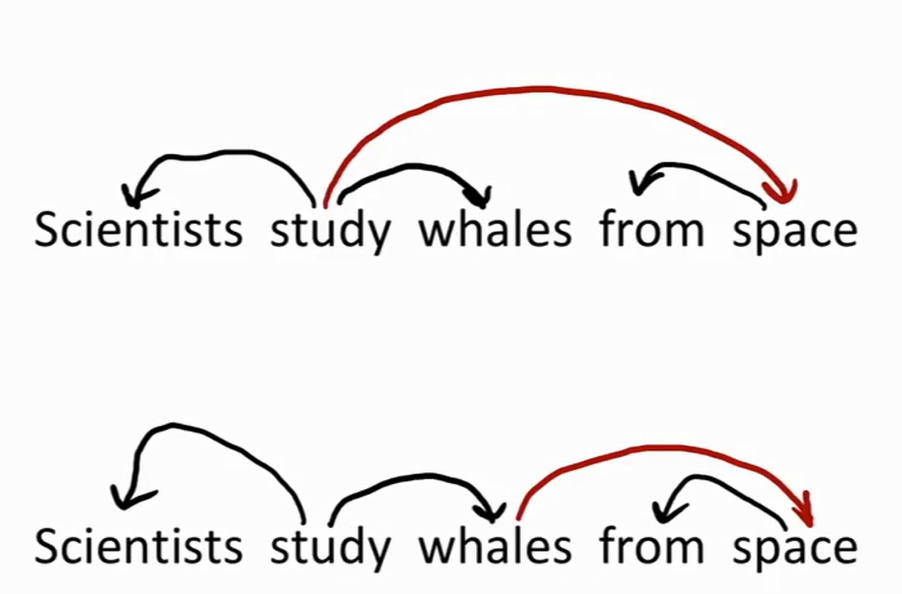
在上面这个歧义的句子中,句子意思的关键在于 “from space” 是修饰 “whales” 还是 “study” 。句子歧义的问题可以被看作是在依存结构中谁修饰谁的问题。
对于 n 个短语来说,组成的树形结构有 $C_n=\frac{(2n)!}{(n+1)!n!}$ 种,又叫做Catalan数。
有一个提供标记的依存数据集,Universal Dependencies
在一开始,建立树库似乎比语法规则更慢,而语法规则似乎更有普适性。但是在机器学习领域,依存树可以合理的解释句子结构。
树库具有以下优点:
- 树库可以复用,而每个人的语法规则都不一样。
- 使用了真实的、覆盖面广的数据,而语法规则依靠直觉
- 含有重要的概率分布信息
- 可以用来评估系统
依存语法与依存结构
90年代的句法分析论文99%都是短语结构树,但后来人们发现依存句法树标注简单,parser准确率高,所以后来(特别是最近十年)基本上就是依存句法树的天下了。
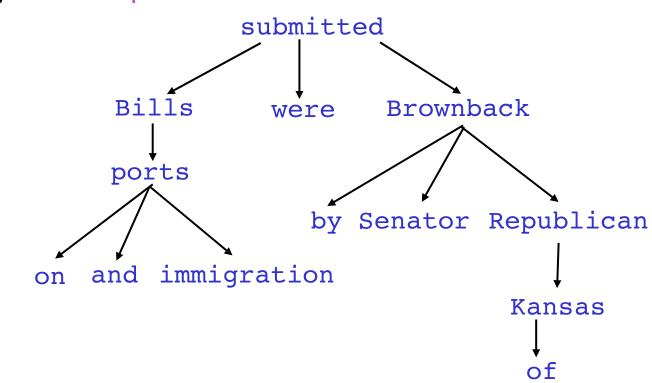
如果没有依存关系标记,上图的树实际上与限制性CFG等价,而通过一些语法关系来给依存关系分类,得到下图,事情就会不一样
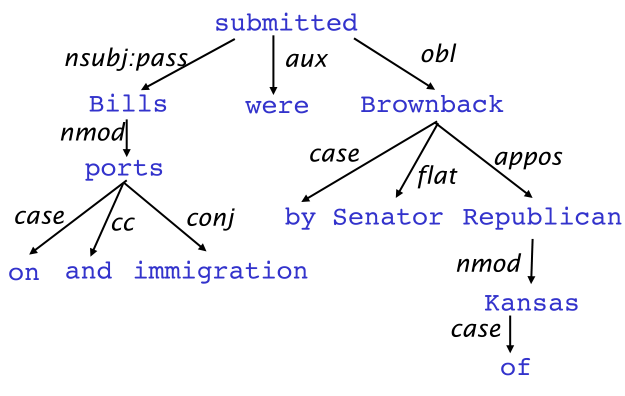
每一个箭头包括一个头部(head)和一个独立项(dependent)
最近提出了一种泛依存(Universal Dependency),主要不同之处在于,介词没有任何dependent
依存分析的发展
Panini 在公元5世纪提出了 Panini 语法
1959年,L. Tesniere,被称为现在依存之父
依存文法在时序比较自由的语言中比较流行(俄语、汉语等),而有序的语言(如英语)适合CFG。
Davis Hays 是美国计算语言学的创始人,在1962年构造了一个英语的依存分析。
怎样做依存分析
分析一个句子的方法,是分析每个词和其他单词的依赖关系。

需要加一些限制:
- 只能有一个单词是ROOT的依赖项
- 不能有环:A->B, B->A
如果依存关系两两不交叉,那么这个依存关系是嵌套的。
完全嵌套的依存树可以被投影到一个平面上,然后得到一个嵌套关系。
英语中大部分依存关系是嵌套的。
提取依存关系的方法:
动态编程法
图算法:最小生成树
约束补偿
确定性依存分析
研究热点
这节课介绍的论文题为《Improving Distributional Similarity with Lessons Learned from Word Embeddings》
我们在前面学习了两类生成词向量的方法:
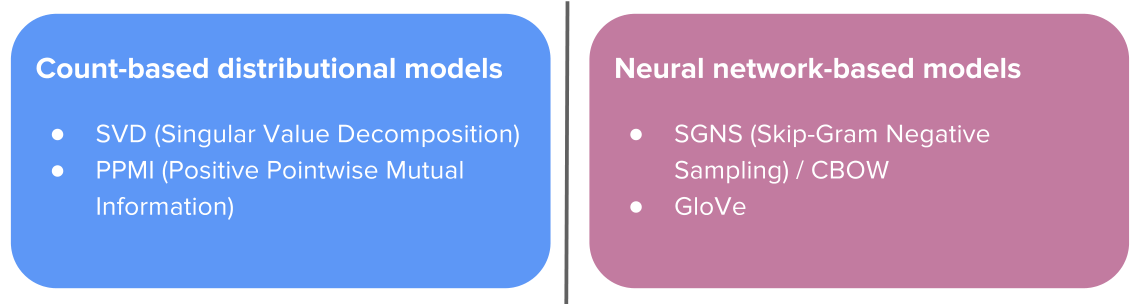
Count-based distributional 模型使用共现矩阵来生成词向量,基于神经网络的方法如负采样的Skip-gram,GloVe
通常认为基于神经网络的方法更好,Levy et. al. 提出是超参和系统的选择更重要,而不是 embedding 算法本身。
作者认为,通过超参数的调整,Count-based distributional 模型的性能接近于神经网络模型,两种方法不能说哪种一定更优。
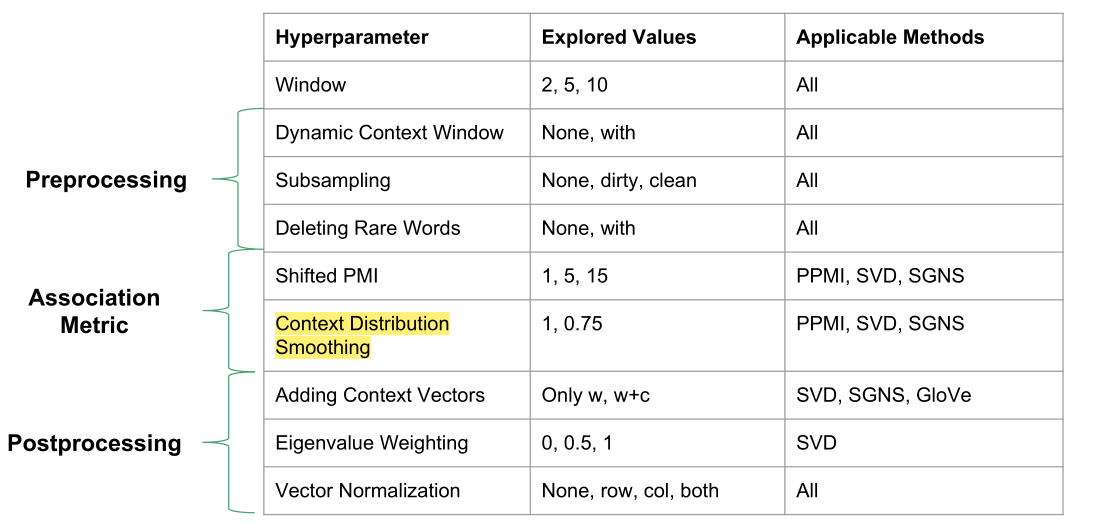
通过调整8个超参数,结果显示没有一致的最优模型。
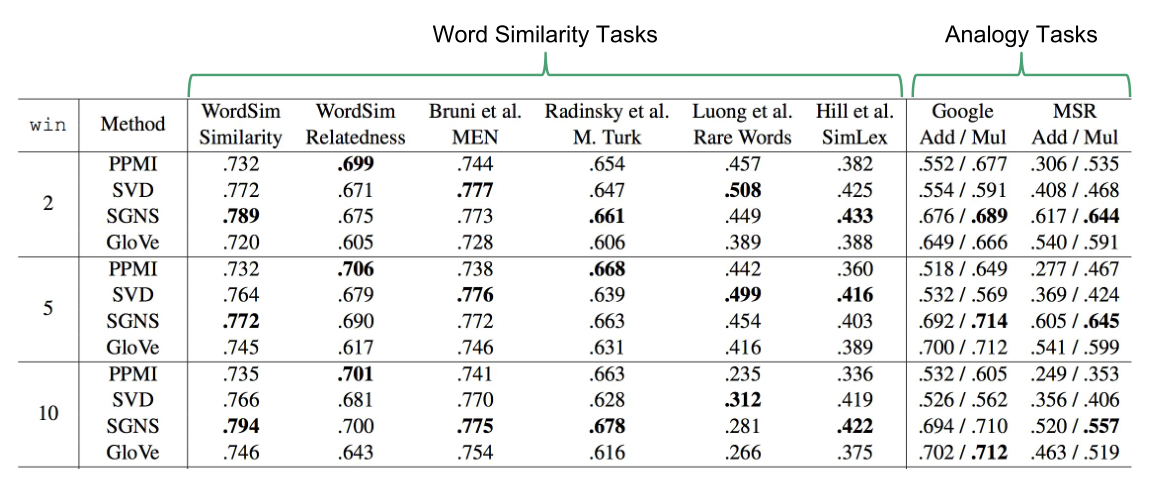
贪婪的基于迁移的依存分析
这里介绍了 arc-standard transition-based parser
我们想要分析句子 “I ate fish”,有一个栈 stack(灰色),一开始只有[root],右端为顶部,还有一个缓冲区 buffer(橙色),缓冲区的左端作为顶部。

在这个分析方法中,有三种操作,分别是:
- shift,把 buffer 顶部弹出,放入 stack 顶部
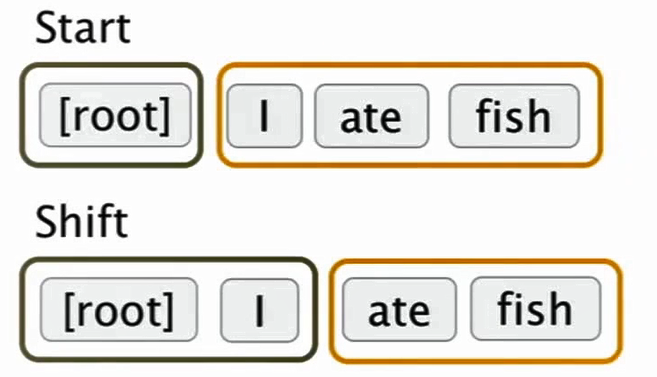
- left-arc,stack 中第二个顶部元素是顶部元素的依赖项,然后把这个依赖项从 stack 中拿走,再 shift 一下,将 fish 放到 stack 中,这样 buffer 就空了
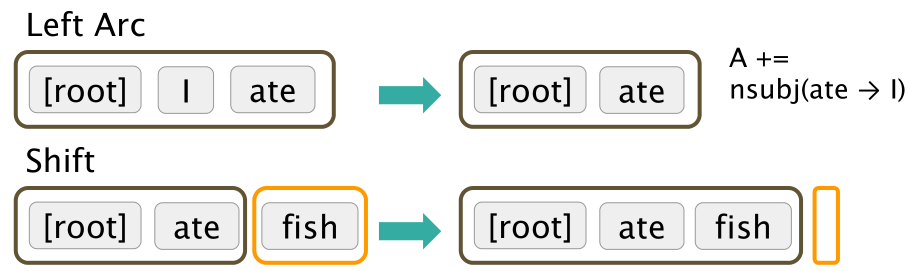
- right-arc,规定 stack 中顶部元素是第二个顶部元素的依赖项
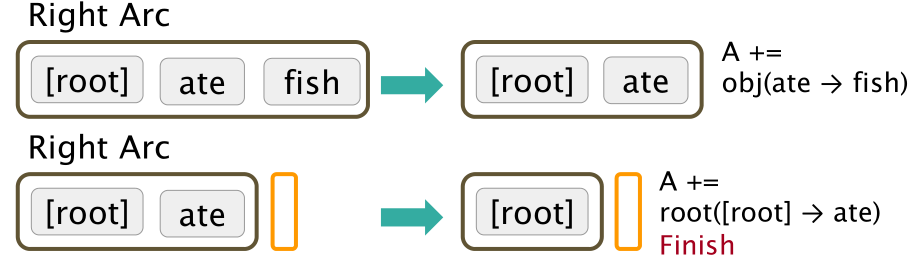
最终 buffer 为空,stack 中只有 [root]
那么如何决定下一步执行什么操作呢?可以用一个分类器来操作。我们在树库中已经有句子的依存树,可以得到从句子中得到这个依存树的唯一的操作序列,这样我们就有了监督数据集。正常情况下不只有三种操作,而是有几十种分类。
下面介绍如何提取特征。
传统的方法考虑所有单词的词性等信息作为特征,这样的时间复杂度是线性的(随句子长度成正比)
依存分析的评估方法:
- UAS:只考虑弧的准确率
- LAS:同时考虑弧和标签的准确率
传统的方法存在以下缺点:
- 特征是稀疏的,有很多没啥用的特征
- 这种传统的特征不能覆盖所有的情况
- 计算如此多的特征代价昂贵
神经网络依存分析
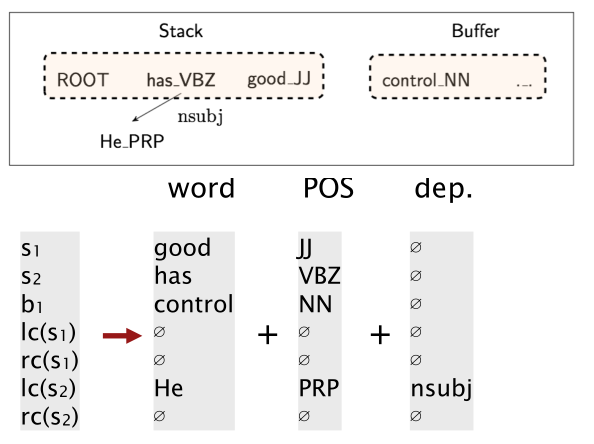
除了将单词用 d 维表示之外,我们还将 POS(词性) 和 依存标签(如名词性主语)用 d 维向量表示。
我们提取特定的位置的特征(top of stack, top of buffer),把词向量、POS 表示、依存关系表示(来自前面建立的弧)合并成一个特征向量。
然后输入一个神经网络模型:
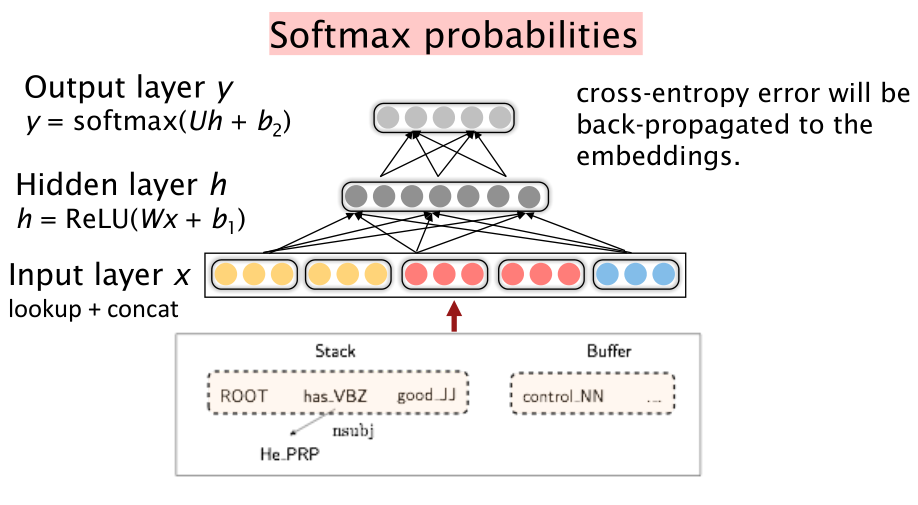
神经网络中的非线性
如果不使用非线性,深度神经网络将是无用的。非线性的作用是把神经元组合起来得到一个近似函数。
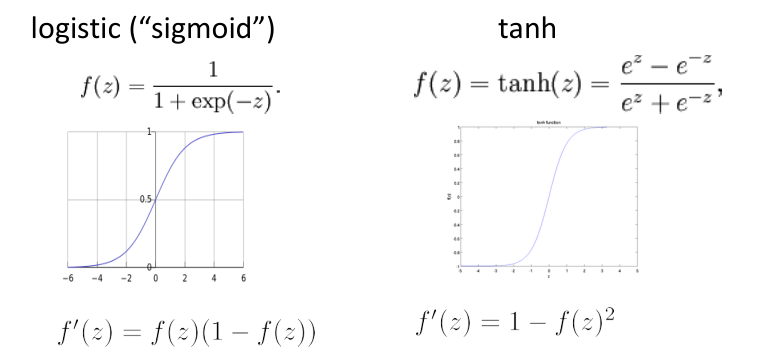
有很多非线性函数可选,ReLU 被证明效果很好。ReLU在反向传播时要么不反馈残差,要么原样反馈残差。
Chen&Manning 的工作被许多人继续往前推进,走在最前沿的是Google,包括:
- 更大更深调参调得更好(更昂贵)的神经网络
- Beam Search
- 在决策序列全局进行类似CRF推断的方法
产生了比如 SyntaxNet 模型,有一个更大更优化的方法。