CS224n Lecture 3 高级词向量表示
高级词向量表示
Finish word2vec
I like deep learning and NLP.
取deep作为中心词,则 $$ p(I\mid deep) = \frac {\exp(uI^Tv{deep})}{\sum_{w=1}^V \exp(uw^T v{deep})} $$
$$ p(the\mid deep) = \frac {\exp(u{the}^Tv{deep})}{\sum_{w=1}^V \exp(uw^T v{deep})} $$
然后向后取下一个窗口。
在每个窗口中,最多有2m+1个单词,所以$\nabla_{\theta}Jt(\theta)$很稀疏: $$ \nabla{\theta}Jt(\theta) = \begin{bmatrix} 0\\vdots\\nabla{v{like}}\\vdots\0\\nabla{u{I}} \\vdots\\nabla{u_{learning}} \\vdots \end{bmatrix} $$
进行梯度下降时并不需要更新整个矩阵,我们使用随机梯度下降SGD,在每个窗口更新矩阵时,只更新特定的列,或者哈希之后通过键值对更新。
在每个窗口计算概率时,都需要遍历所有的词(如果词表大小为20000,则需要做20000次内积运算),效率很低。
因此采用负采样的方法,选取一些不同时出现的负样本,最小化这些词出现在中心词附近的概率,同时最大化真实的输出词出现的概率。
在第t个窗口上的目标函数表示为: $$ J_t(\theta) = \log\sigma(u_o^Tvc)+\sum{j\sim P(w)}[\log \sigma(-u_j^Tv_c)] $$
$$ P(w) = U(w)^{3⁄4}/Z $$
为了更多的采样低频词,所以取指数3/4。
整体目标函数$J(\theta)=\frac{1}{T}\sum_{t=1}^TJ_t(\theta)$,但是实际上并不经过所有的窗口然后做一次大的梯度更新,因为效果不好。
总结:
- 遍历语料库中的所有单词
- 预测每个单词的周围单词
- 捕捉单词的共同点
其他方法
在word2vec之前的方法,遍历整个文档,使用共同出现的计数结果进行计算(潜在语义分析),下图就是一个共现矩阵(co-occurrence):
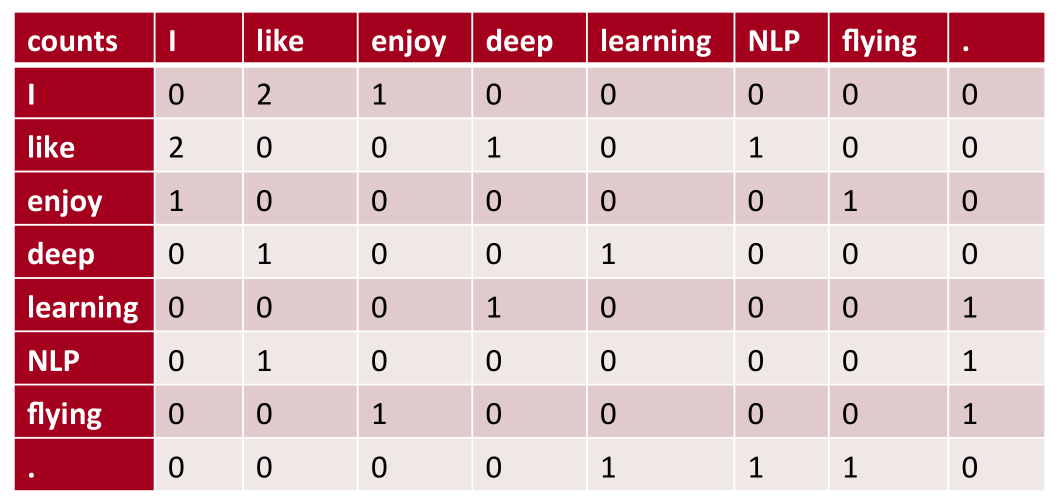
此时,矩阵的一行可以直接用来做词向量,但是维数会很大,因此要降维到25-1000维
可以使用SVD(奇异值分解)处理共现矩阵的方法得到词向量,但是也存在问题:
词的长尾效应,频繁出现的词(如the,he)并没有很多信息,可以规定最大共现次数为100或直接忽略频繁词;另一种方法是把靠近中心词的出现记为1,在窗口边缘的记为0.5;也可以用计算词的相关性来代替计数。
SVD虽然简单,但是如果矩阵很大,那么计算耗时就会很大,并且很难加入新的词或者文档。
Count based vs direct prediction
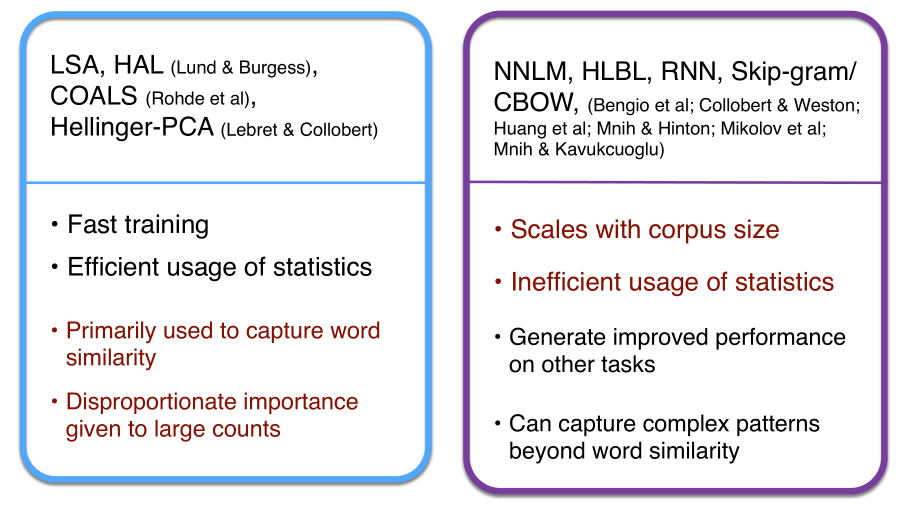
基于计数的方法(上图左)大多数是基于SVD和共现矩阵,在中小规模语料训练很快,有效地利用了统计信息。但用途受限于捕捉词语相似度,也无法拓展到大规模语料。
而NNLM, HLBL, RNN, Skip-gram/CBOW这类使用窗口进行预测的模型必须遍历所有的窗口训练,也无法有效利用单词的全局统计信息。但它们显著地提高了下游NLP任务,其捕捉的不仅限于词语相似度。
GloVe
尝试组合上述两种方法,最终结果是GloVe模型。
目标函数是: $$ J(\theta) = \frac{1}{2}\sum{i,j=1}^Wf(P{ij})(u_i^Tvj-\log P{ij})^2 $$ $P{ij}$是两个词的共现频率。 $$ X{final} = U + V $$ 最终输出的结果是把输入输出两个向量相加,看起来不符合直觉,但是在实际应用中效果很好。
skip-gram模型试图一次捕获同时出现的一个窗口,而GloVe模型试图捕获总体统计数据。
多义词polysemy
这一部分由Arun Chaganty介绍了《Linear Algebraic Structure of Word Senses, with Applications to Polysemy》这篇论文。
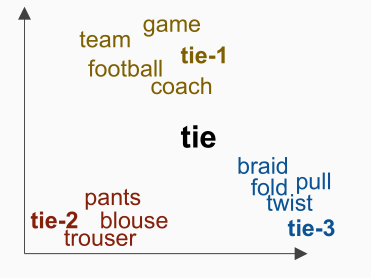
对于多义词tie,它可以表示比赛的平局,可以表示衣服的领带,也可以表示一种扭曲的动作。
实际得到的词向量是多个词向量(tie-1,tie-2,tie-3)的线性叠加。
那么如何得到tie对具体某个意思的表示呢,只是介绍了可以通过稀疏编码恢复,这里并没有讲更多的细节。
评估单词向量
有两种方法:Intrinsic(内部) vs extrinsic(外部)
Intrinsic:专门设计单独的试验,由人工标注词语或句子相似度,与模型结果对比。好处是是计算速度快,但不知道对实际应用有无帮助。有人花了几年时间提高了在某个数据集上的分数,当将其词向量用于真实任务时并没有多少提高效果。
Extrinsic:通过对外部实际应用的效果提升来体现。耗时较长,在进行外部评估时,必须只同时改变一个部分。
单词向量类比
单词向量类比(word vector analogies)是一种内部评估的方法。

men相对于woman就像king相对于queen,因此queen对应的词向量应该与$x{woman}-x{man}+x_{king}$有最大的余弦相似度。
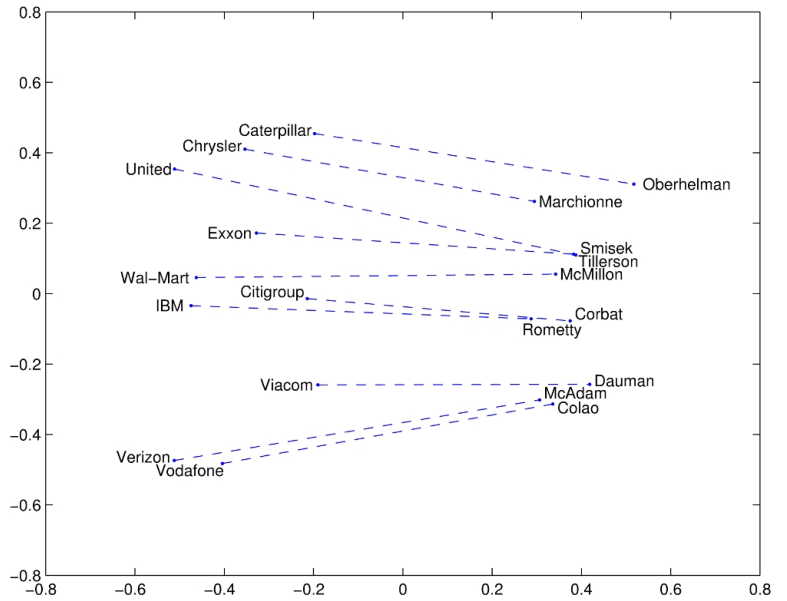
同理,一家公司CEO的向量减去公司名字的向量加上另一家公司名字的向量,就应该得到这家公司CEO的向量。
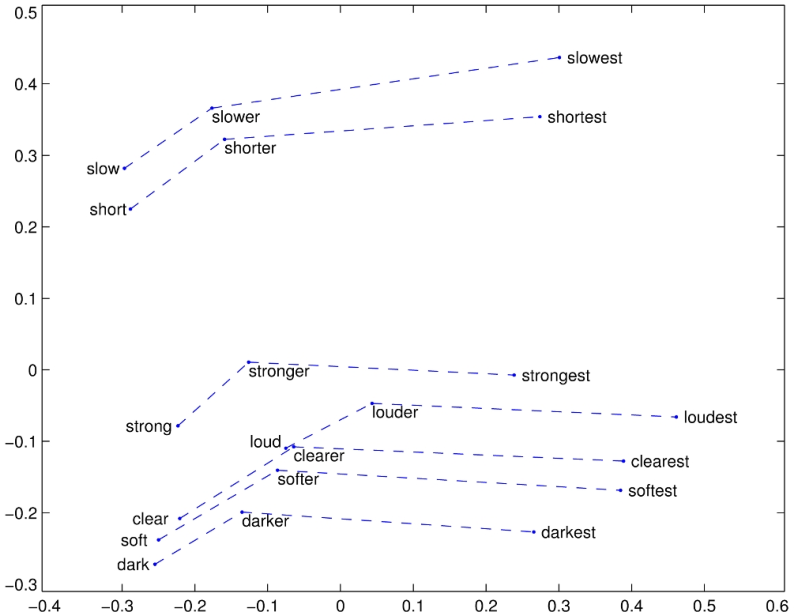
这同样也适用于句法关系,如上图,比较级总是出现在最高级的前面。
这种方法可以用了量化词向量的效果,人们提出了一个数据集来做这样的工作,有几千的类似的类比关系可以用来调整超参数。
另一种内部评估方法是人工对词语相似度打分,然后希望余弦相似度与人工相似度最接近。
超参数调整
大约300维,窗口大小8的对称窗口效果挺好的,考虑到成本。
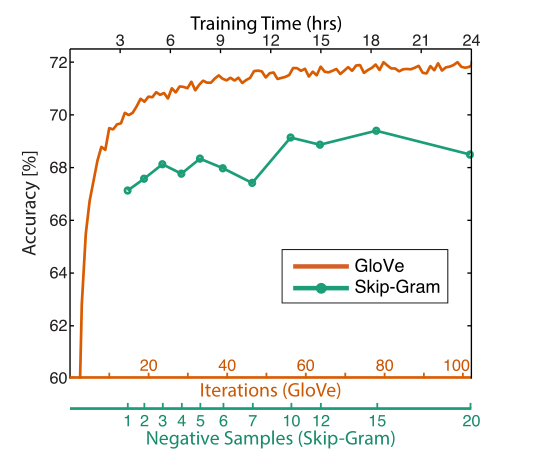
对GloVe来讲,迭代次数越多越好,效果很稳定。
训练数据越多越好。
外部评估
可以通过下游任务NER(明明实体识别)来评估词向量的效果。
GloVe在下游任务上完成的最好。