CS224n Lecture 4 词分类
词分类
本节课构建了一个简单的神经网络模型进行词分类任务,因为单独的词分类任务很少见,所以举了一个NER(命名实体识别)任务的例子,并详细介绍了使用梯度下降进行优化的计算过程。
一些标记
通常有一个训练集 $$ {x_i,yi}^N{i=1} $$ x是input,比如单个单词或词向量,上下文窗口;y是label,可以是感情倾向,或是命名实体,词序列等。
在机器学习领域,分类问题可以被认为是简单的逻辑回归,也就是学习一个决策边界。
通常x是确定的,只学习逻辑回归的权重W
Softmax
$$ p(y\mid x)=\frac{\exp(Wy\cdot x)}{\sum{c=1}^C\exp(W_c\cdot x)},W\in\mathbb{R}^{C\times d} $$
我们可以把计算过程分成两部分
- 对于所有的分类,计算$f_c = W_c\cdot x$
- 通过归一化,将向量输入softmax,计算得到概率分布
我们希望模型可以最大化正确输出的概率,最大化概率=最大化对数概率=最小化对数概率的负数,取对数概率的负数最为目标函数,也就是交叉熵误差
假设真实(truth or gold or target)概率分布为为p=[0,0,…,1,0],即正确的为1,其余为0,而计算出的概率分布为q,那么交叉熵为: $$ H(p,q) = -\sum_{c=1}^Cp©\log q© $$ 因为p是one-hot的,所以交叉熵等于对数概率的负数。
整个数据集上的交叉熵损失函数为: $$ J(\theta)=\frac{1}{N}\sum{i=1}^N-\log(\frac{e^{f{yi}}}{\sum{c=1}^Ce^{f_c}}) $$ 其中 $$ f_y = f_y(x)=Wy\cdot x=\sum{j=1}^dW_{yj}x_j $$ 也可以表示为矩阵形式$f=Wx$
在实际应用中还会用到正则项,为了鼓励模型中的所有权值尽可能小,避免过拟合: $$ J(\theta)=\frac{1}{N}\sum{i=1}^N-\log(\frac{e^{f{yi}}}{\sum{c=1}^Ce^{f_c}})+\lambda\sum_k\theta_k^2 $$ 如果训练集较小,应该在一个大的语料库上训练词向量,然后在训练分类器时保持词向量不变,否则会失去泛化性;如果训练集很大,则可以随即初始化词向量然后学习它。
window classification
事实上,单独对词进行分类很少见,实际上想做的是在上下文中对单词进行分类。
第一个例子是命名实体识别任务,对语料库中的每个单词,识别是人名、地名、组织名还是其他。

上图描述了这一任务,取长度为2的词窗口,把中间词的标签作为窗口的标签进行分类。
最简单的方法就是把五个词向量的拼接放入softmax分类器,下面介绍如何更新词向量:
更新词向量
规定$\hat{y}$为softmax输出向量,t为目标概率分布
链式法则为: $$ y=f(u), u=g(x), y=f(g(x)) $$
$$ \frac{dy}{dx}=\frac{dy}{du}\frac{du}{dx}=\frac{df(u)}{du}\frac{dg(x)}{dx} $$
$$ \frac{\partial}{\partial x}-\log softmax(fy(x))=\sum{c=1}^C -\frac{\partial \log softmax(f_y(x))}{\partial f_c}\cdot \frac{\partial f_c(x)}{\partial x} $$
$$ \frac{\partial}{\partial f}-\log softmax(f_y)=\begin{bmatrix} \hat{y}_1\\vdots\\hat {y}_y - 1\\vdots\\hat y_C \end{bmatrix}=[\hat y-t]=\delta $$
上面的推导是作业的一部分 $$ \sum_{c=1}^C -\frac{\partial \log softmax(f_y(x))}{\partial f_c}\cdot \frac{\partial fc(x)}{\partial x}=\sum{c=1}^C\delta_cW_c^T $$
$$ \frac{\partial}{\partial x}-\log p(y\mid x)=\sum_{c=1}^C\delta_cW_c^T=W^T\delta $$
$$ \nabla_xJ=W^T\delta\in\mathbb{R}^{5d} $$
得到了窗口的梯度,但是我们想更新的是词向量而不是整个窗口,只需拆分总体梯度。 $$ \nablaxJ=\delta{x{window}}=\begin{bmatrix}\nabla{x{museums}}\\nabla{x{in}}\\nabla{x{Paris}}\\nabla{x{are}}\\nabla{x_{amazing}}\end{bmatrix}\in\mathbb{R}^{5d} $$
然后计算 $J$ 关于softmax的权值 $W$ 的梯度,得到整个模型的总体梯度 $$ \nabla{\theta}J(\theta)=\begin{bmatrix}\nabla{W{1}}\\vdots\\nabla{W{d}}\\nabla{x{aardvark}}\\vdots\\nabla{x_{zebra}}\end{bmatrix}\in\mathbb{R}^{Cd+Vd} $$ 这个梯度是十分稀疏的,更新时没必要在每个窗口都发送全部梯度。
在更新过程中计算代价最高的是矩阵运算$f=Wx$和指数运算,这里矩阵运算比循环要快多了
%timeit [W.dot(wordvectors_list[i]) for i in range(N)]
# 756 µs ± 5.5 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%timeit W.dot(wordvectors_one_matrix)
# 43.6 µs ± 442 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Softmax与神经网络
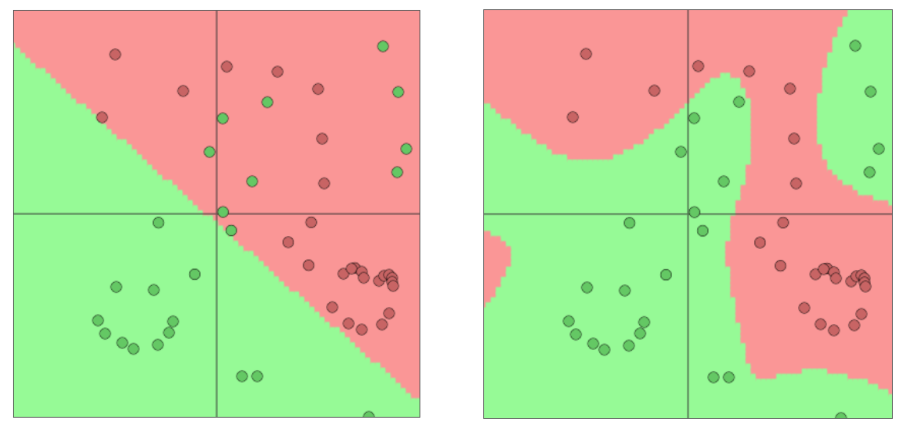
Softmax(=对数几率回归)只能得到线性的决策边界(左),而神经网络能够得到更复杂的非线性决策边界(右)。
神经网络中的一个神经元可以被视为一个二元对数几率回归单元: $$ h_{w,b}=f(w^Tx + b) $$
$$ f(z)=\frac{1}{1+e^{-z}} $$
那么神经网络可以被视为同时进行多个对数几率回归,但是并不强制输出结果,因为前一层的输出被当做下一层的输入。用最后一层的损失函数来控制前面的隐藏层。
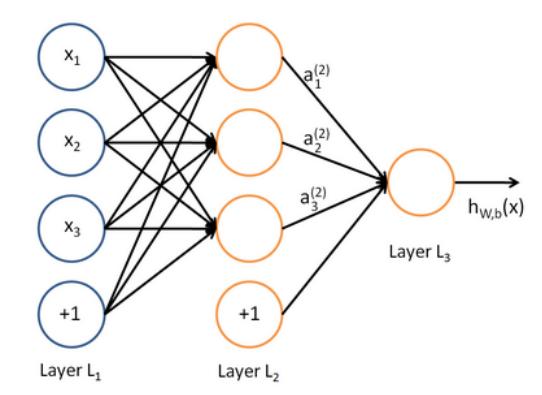
引入神经网络
下面是一个简单的3层神经网络 $$ z = Wx + b $$
$$ a = f(z) $$
$$ p(y\mid x)=\text{softmax}(Wa) $$
在下面这个NER任务中,使用一个未归一化的分数替代softmax。
$$
score(x)=U^Ta\in\mathbb{R}
$$
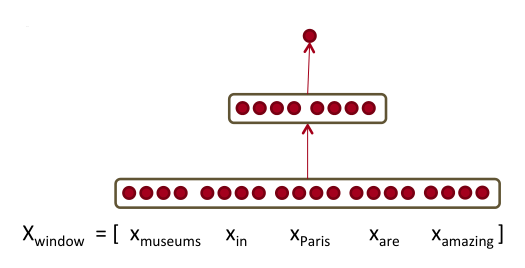
输入是一个20维的向量,将其定义为列向量,假设第一个隐藏层有8个单元,W的维度则为8行20列。任务的目标是判别输入的这个窗口的中心词是否是一个地名。 $$ x\in\mathbb{R}^{20\times 1}, W\in\mathbb{R}^{8\times 20},U\in\mathbb{R}^{8\times 1} $$ 中间层的作用是学习不同词向量之间的非线性相互作用,例如如果前一个单词是”in”,则中心词是地名的概率会增加。
##### 最大间隔损失函数
目标是使得正确的窗口的得分更高,而错误窗口的得分更低。 $$ J=\max(0,1-s+s_c) $$ s = score(museums in Paris are amazing),即正确窗口
sc = score(Not all museums in Paris),即错误窗口
使用反向传播训练
$$ \frac{\partial s}{\partial W}=\frac{\partial}{\partial W}U^Ta=\frac{\partial}{\partial W}U^Tf(z)=\frac{\partial}{\partial W}U^Tf(Wx+b) $$
并不需要考虑所有的权重,因为一个a只与一个W有关 $$ \frac{\partial}{\partial W{ij}}U^Ta \rightarrow\frac{\partial}{\partial W{ij}}U_ia_i $$
$$
\begin{align}
Ui\frac{\partial}{\partial W{ij}}a_i &= U_i\frac{\partial a_i}{\partial z_i}\frac{\partial zi}{\partial W{ij}}
&= U_i\frac{\partial f(z_i)}{\partial z_i}\frac{\partial zi}{\partial W{ij}}
&= U_i f’(z_i) \frac{\partial zi}{\partial W{ij}}
&= U_i f’(zi) \frac{\partial W{i\cdot}x+bi}{\partial W{ij}}
&= U_i f’(zi) \frac{\partial}{\partial W{ij}}\sumk {W{ik}x_k}
&= U_i f’(z_i) x_j
&= \delta_i x_j
\end{align}
$$
我们得到
$$
\frac{\partial s}{\partial W_{ij}}=U_if’(z_i)x_j=\delta_ixj
$$
现在的问题是,为了得到对整个矩阵W的一个梯度,应该怎样组合这些元素,最终我们得到:
$$
\frac{\partial s}{\partial W}=\delta x^T
$$
接下来,以只含有两个隐藏层单元的神经网络为例,计算s对x的偏导数
$$
\begin{align}
\frac{\partial s}{\partial x{i}} &= \sum_{i=1}^2\frac{\partial s}{\partial a_i}\frac{\partial ai}{\partial x{j}}
&= \sum_{i=1}^2\frac{\partial U^Ta}{\partial a_i}\frac{\partial ai}{\partial x{j}}
&= \sum_{i=1}^2 U_i \frac{\partial f(Wix+b)}{\partial x{j}}
&= \sum_{i=1}^2 U_if’(Wix+b) \frac{\partial W{i\cdot}x}{\partial x{j}}
&= \sum{i=1}^2 \deltaiW{ij}
&= W_{\cdot j}^T\delta
\end{align}
$$
$$ \frac{\partial s}{\partial x}=W^T\delta $$
最终总体的目标函数为:
