CS224n Lecture 5 反向传播算法
反向传播算法
本节课是对反向传播算法的详细介绍,使用勒四种方法来介绍反向传播。
在很多情况下,反向传播将只是一个抽象的概念,只需要调包就能实现功能。但是在实际操作过程中可能会遇到问题,如果没用真正理解反向传播,就不知道产生问题的原因。
第一种解释
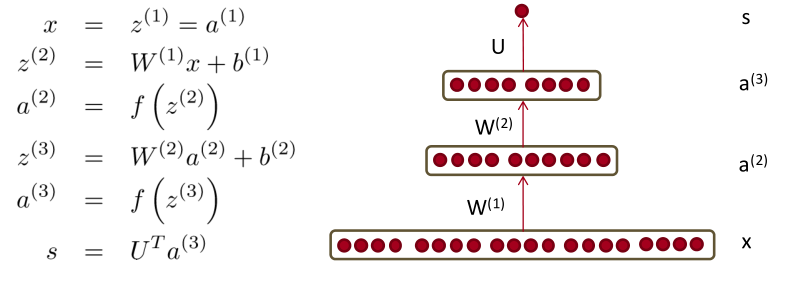
上图是一个含有两个隐藏层的神经网络模型,最后的score的计算方法与上一节课相同。
$$
\begin{align}
s &= U^Tf(W^{(2)}f(W^{(1)}x+b^{(1)})+b^{(2)})
&= U^Tf(W^{(2)}a^{(2)}+b^{(2)})
&= U^Ta^{(3)}
\end{align}
$$
由之前的推导$\frac{\partial s}{\partial W_{ij}}=U_if’(z_i)x_j=\delta_ix_j$
可得类似的梯度 $$ \frac{\partial s}{\partial W_{ij}^{(2)}}=U_if’(z_i^{(3)})a_j^{(2)}=\delta_i^{(3)}a_j^{(2)} $$ 在整个矩阵的维度 $$ \frac{\partial s}{\partial W^{(2)}}=\delta^{(3)}a^{(2)^T} $$
$$ \text{where} \quad \delta^{(3)}=U\otimes f’(z^{(3)}) $$
继续推导 $$ \frac{\partial s}{\partial W^{(1)}}=\delta^{(2)}x^T $$
$$ \text{where} \quad \delta^{(2)}=(W^{(2)^T}\delta^{(3)})\otimes f’(z^{(2)}) $$
我们可以得到对任意层l的梯度推导 $$ \frac{\partial}{\partial W^{(l)}}E_R=\delta^{(l+1)}(a^{(l)})^T+\lambda W^{(l)} $$
$$ \text{where} \quad \delta^{(l)}=\Bigl((w^{(l)})^T\delta^{(l+1)}\Bigr)\otimes f’(z^{(l)}) $$
顶层和底层也可以用这个公式,只不过误差$\delta$ 更简单
第二种解释
第二种解释没有涉及到神经网络。
函数$f(x,y,z)=(x+y)z$可以用下图表示:
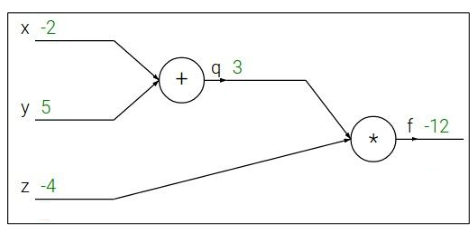
我们定义$q=x+y,\quad f=qz$,根据链式法则计算各个导数。
以计算$\frac{\partial f}{\partial x}$为例,先计算$\frac{\partial f}{\partial q}$再计算$\frac{\partial q}{\partial x}$,用下一层节点的值乘以上一层节点的值。
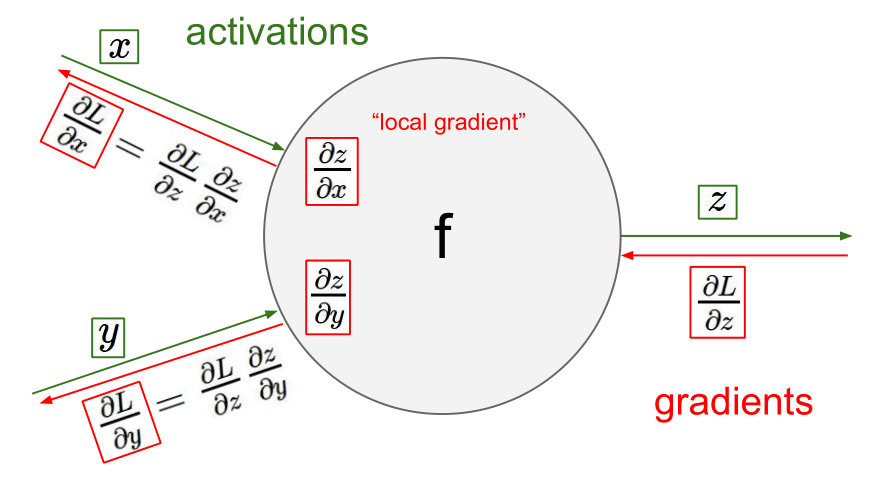
如上图,这种方法把所有的函数都看做路线。计算时首先前向传播计算函数的值(如通过x和y计算z的值),然后反向传播计算梯度。在反向传播的过程中,从更高层的节点得到梯度信号($\frac{\partial L}{\partial z}$),再根据链式法则计算低层的梯度($\frac{\partial L}{\partial x}=\frac{\partial L}{\partial z}\frac{\partial z}{\partial x}$),并向后传播。
另一个例子 $$ f(w,x)=\frac{1}{1+e^{-(w_0x_0+w_1x_1+w_2)}} $$ 画成路线图如下图所示:
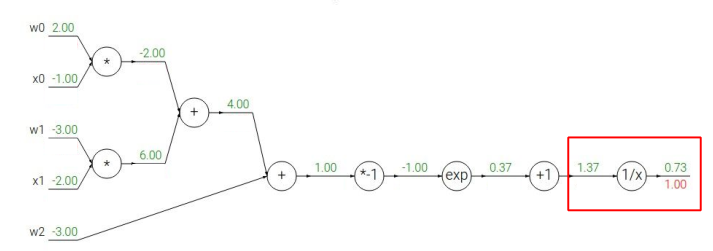
首先前向计算函数的值,然后反向计算各个节点的梯度值。
第一个节点的梯度值为$\frac{\partial f}{\partial f} = 1$
第二个节点的梯度值为$1*\frac{-1}{1.37^2}=-0.53$
依次向后类推,计算得到梯度值如下:
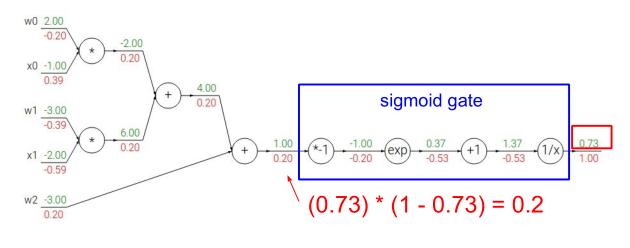
也可以将sigmoid函数的操作合并起来作为路线上的一个节点 $$ \sigma(x)=\frac{1}{1+e^{-x}} $$
$$ \frac{d\sigma(x)}{dx}=(1-\sigma(x))\sigma(x) $$
#####第三种解释
流动图
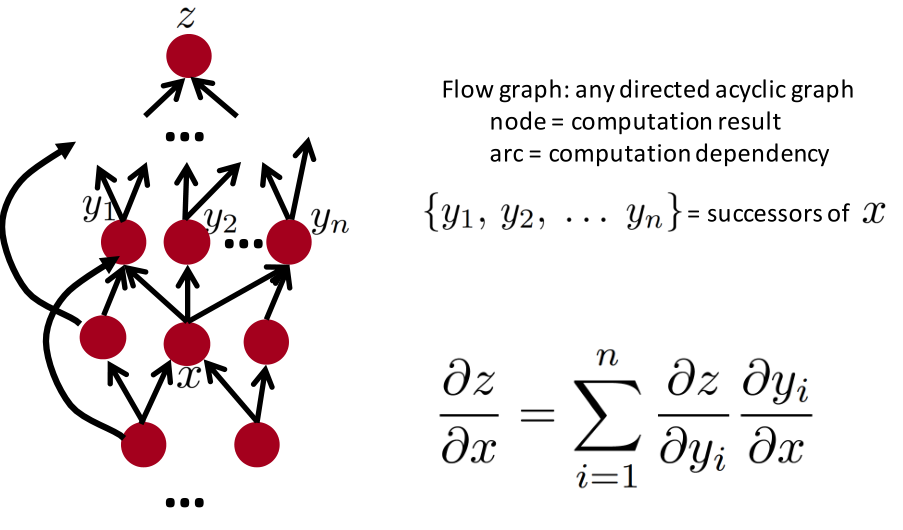
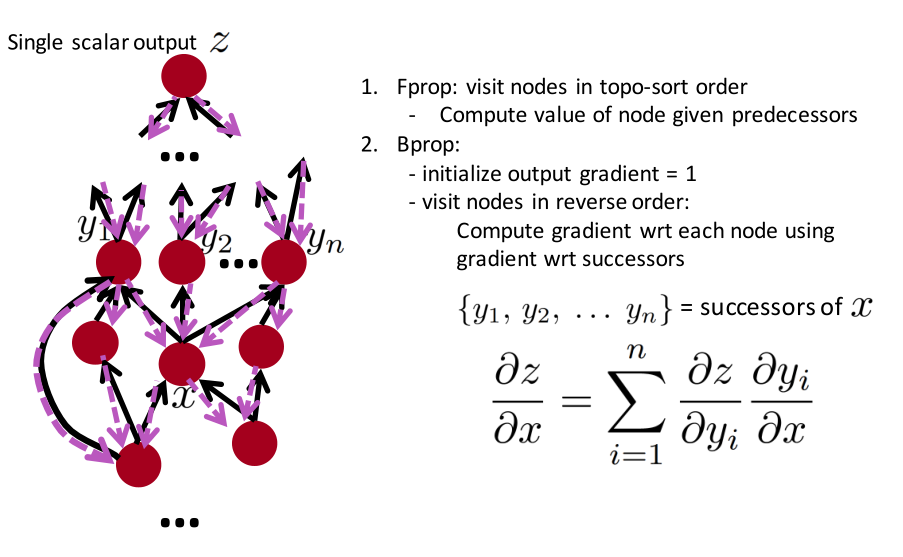
前向计算每个结点的值,再反向计算每个结点的梯度。
第四种解释
第四种解释把前面的综合了起来,还是以一开始的神经网络为例。
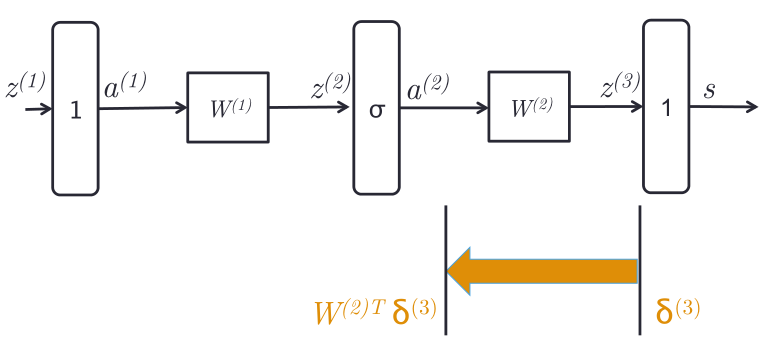
假设有误差信号$\delta ^{(3)}$,穿过$w^{(2)}$之后,得到对$a^{(2)}$的导数。
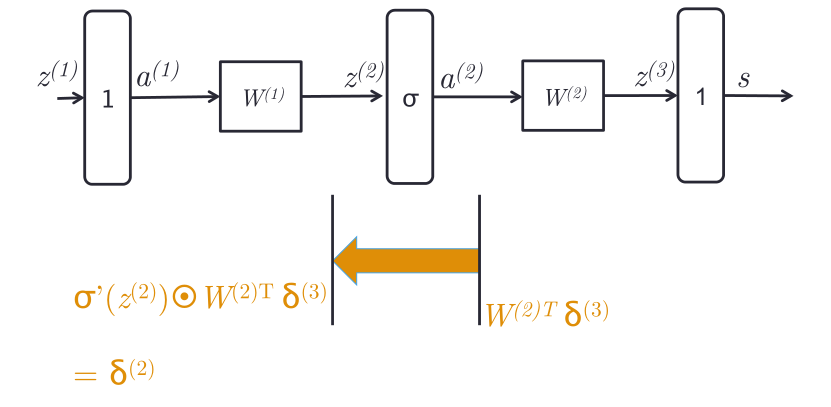
然后穿过$\sigma $到达$W^{(1)}$,得到导数如上图。
fastText
Bag of Tricks for Eficient Text Classification
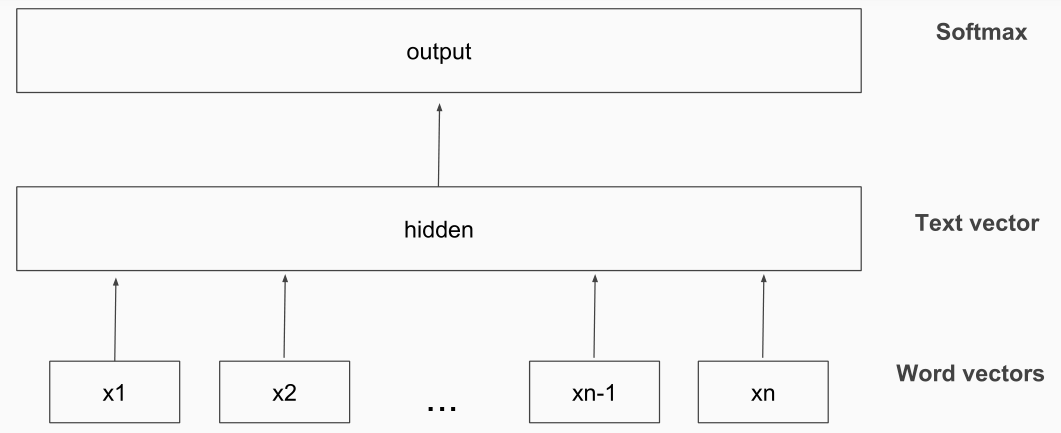
介绍了一种叫 fastText 的线性文本分类模型,模型结构如下:
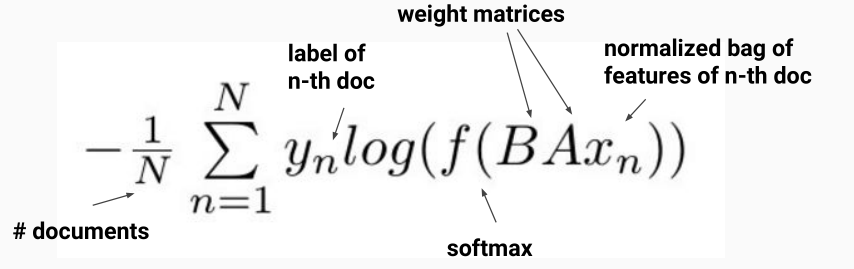
损失函数为:
使用了层级的Softmax
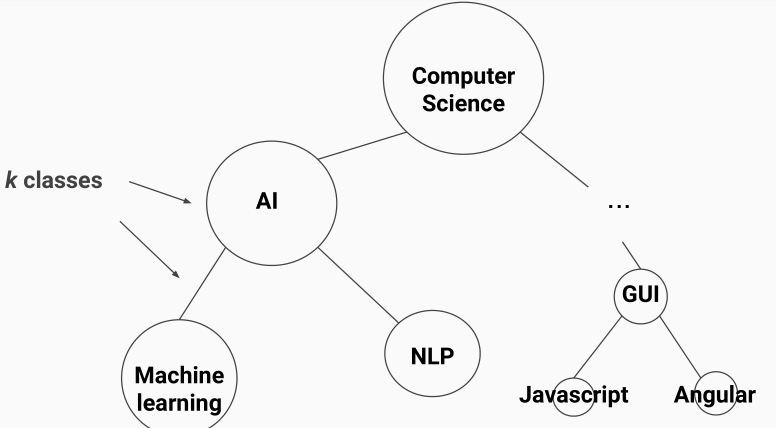
将大的分类再划分成小的分类,可把复杂度由 O(kh) 降低到 O(h logk)。
这种方法比神经网络快了很多,并且效果也不差。
项目建议
接下来讲了一些和课程大作业有关的事情,不再赘述。
评价指标:F1,BLEU,ROUGE等